LSM Tree
LSM Tree
LSM Tree
- Log Strutured Merge Tree
- 适合写多读少的场景
- 核心思路: 顺序写快于随机写
顺序写存在的问题
- 数据冗余
- 不论新增、修改、删除, 都是顺序多加一条记录
- 因此存在一组kv对应多份冗余记录的情况
- 读性能低
- 因为有多份数据, 因此只能通过反向查找, 找到第一个满足条件的kv数据
- 时间复杂度O(n)
结构
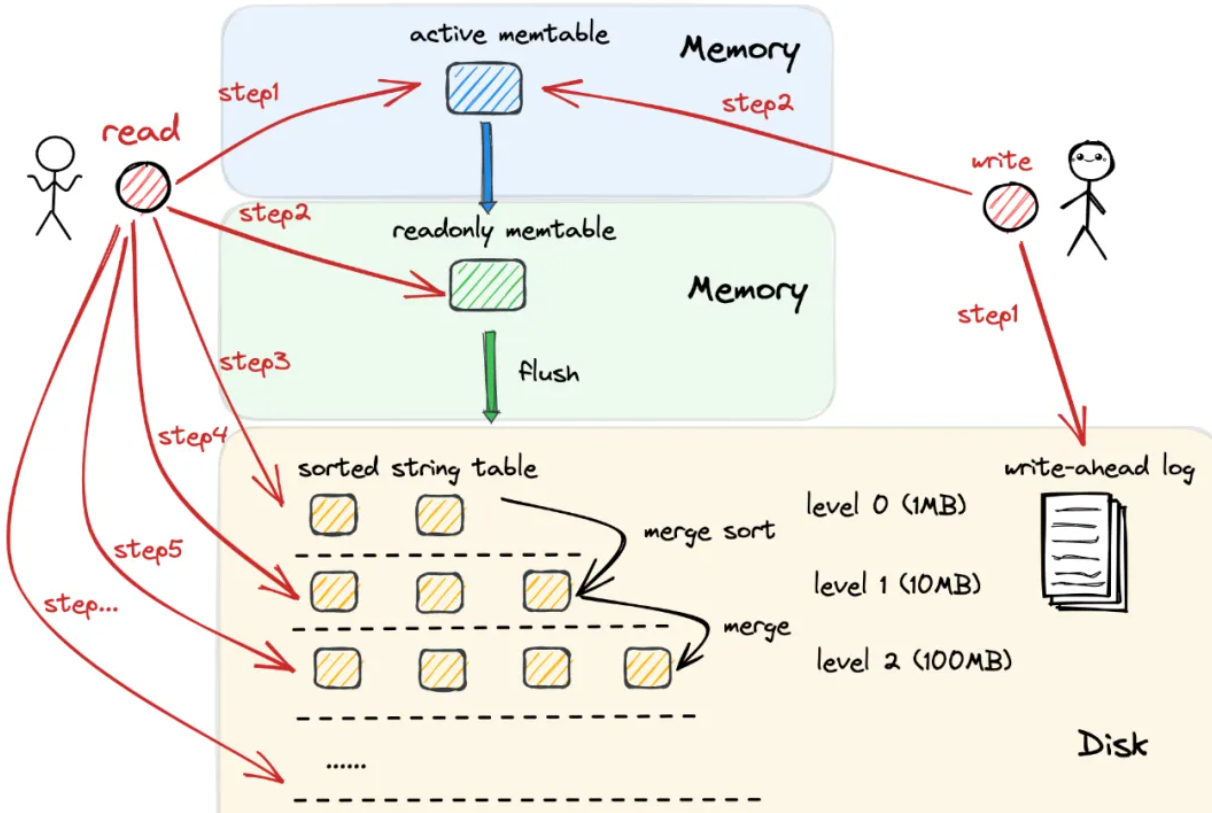
核心设计
memtable
- memtable在内存中缓存
- memtable是按k排序的, 内部有序
- 写操作为就地写(而非顺序写)
- 当memtable被写满之后就会溢写到磁盘distable中
- 在溢写期间的写操作要阻塞, 带来性能问题
- 因此memtable分为active memtable和read-only memtable
- 每当memtable需要溢写时, 就将其一分为二, 将已有的旧数据归属到read-only memtable, 成为一个只读的数据结构, 专注于执行将其溢写到磁盘的流程
- 同时, 建立一个全新空白的active memtable, 作为写操作的新入口, 这样两个流程之间就实现了解耦, 写操作不再需要阻塞
- memtable内部使用跳表实现
wal
- 当发生宕机时, memtable数据就丢失了
- 因此采用wal, 将操作追加写到日志中
- 通过重放可以恢复memtable数据
- 当一个memtable成为distable中, 对应的wal就可以删除
disktable
- disktable内部是有序的, 因为memtable是有序的
- disktable内部无数据重复, 因为memtable是就地写
- 但在disktable之间是可能存在重复和失序的, 全局是无需的
- 引入disk level分层
- 从level-0到level-k, 容量逐渐增大, 数据由小level流向大level
- 当level-i数据过多时, 数据就会从level-i流向level-(i+1), 同时进行归并操作
- 通过归并和去重, 保证到了level-(i+1)中, 数据是有序无重复的
- level-0是特殊的, 因为它的数据全部来自memtable, 是没法通过归并保证数据有序和无重复的
sstable
- sorted string table
- disktable对应的数据结构就是sstable
- sstable会将一个table拆分成若干个block
- 同时维护索引信息记录每个block的k_min和k_max
- tsm tree也会维护一个全局索引信息, 记录不同level中, 每个sstable的k_min和k_max
- 每个sstable维护一个布隆过滤器(bloom fiter)
- 用于快速判断k是否在sstable中
This post is licensed under CC BY 4.0 by the author.