Go Distrubuted Cache Project
Go Distrubuted Cache Project
Distrubuted Cache Project
Introduction
- 模仿groupcache, go语言版的memcached
- 缓存大量存在于计算机系统中
- Redis
- CDN
- 设计分布式缓存需要考虑
资源控制,淘汰策略,并发,分布式节点通信等问题
Reason
内存kv缓存的缺点 -> map[key]value
- 内存不够
- 选择缓存删除 -> 缓存淘汰策略
- 并发写入冲突
- 加锁
- 单机资源不够
- 分布式
Function
- 支持单机缓存和基于HTTP的分布式缓存
- 使用LRU策略 -> 缓存淘汰
- LRU实现 -> map + 双向list
- 加锁避免缓存击穿
- 缓存击穿: 热点数据过期
- 互斥锁
- 缓存雪崩: a.大量key过期; b.缓存挂掉
- a.互斥锁; 后台更新; 均匀设置key的过期时间
- b.限流; 熔断
- 缓存穿透: cache和db都不存在的key
- 禁止不合法请求
- 缓存null或default value
- 布隆过滤器
- bit array + N个Hash
- 缓存击穿: 热点数据过期
- 负载均衡 -> 挑选peer的策略
- random
- RR
- 一致性哈希
- 哈希环
- 虚节点 -> 数据倾斜
- protobuf压缩数据
- 序列化方式
- JSON & protobuf
- JSON可读性更好; protobuf二进制压缩, 效率更高
- Go gob (go binary)
- 二进制压缩, Go语言专用
- JSON & protobuf
- 序列化方式
Detail
淘汰策略
- LRU
- map + 双向list
- 查找O(1), 插入队首、删除队尾O(1), 将元素移动到队首O(1)
- map + 双向list
- LFU
- FIFO
互斥
- sync.Mutex 互斥锁
- sync.RWMutex 读写锁(读锁+写锁)
- 读锁之间不互斥
- 写锁之间、写锁和读锁间互斥
- 性能比较
- 读多写少(读写9:1) -> 读写锁性能远远高于互斥锁
- 读少写多(读写1:9) -> 性能相当
- 读写一致(读写5:5) -> 读写锁性能高
- Mutex原理
- Mutex有正常态(非公平锁)和饥饿态(公平锁)
- 正常态goroutine获取锁的方式
- 当一个goroutine持有锁时, 其它goroutine会先自旋, 若自旋超过一定次数或等待时间超过一定限度, 进入阻塞态
- 自旋: 循环检查锁状态
- 阻塞态的goroutine进入FIFO的等待队列
- 当等待队列的goroutine唤醒时, 会和当前正在执行的goroutine(也就是正在自旋没有进入等待队列的goroutine)竞争
- 这种竞争对刚唤醒的goroutine时不利的, CPU上的goroutine会更有可能获得Mutex
- 当一个goroutine持有锁时, 其它goroutine会先自旋, 若自旋超过一定次数或等待时间超过一定限度, 进入阻塞态
- 正常态下的Mutex更高效, 因为会自旋, 减少了goroutine状态切换的开销
- 一个goroutine等待锁的时间超过阈值时, Mutex会从正常态切换到饥饿态
- 饥饿态goroutine获取锁的方式
- 饥饿态的Mutex会直接将所有权交给等待队列的队首goroutine
- 新请求Mutex的goroutine不会自旋, 直接进去等待队列的队尾
- 等待队列的goroutine按照顺序依次获取Mutex
- 饥饿态的Mutex更公平, 但是性能下降(增加了goroutine状态切换的开销), 但是饥饿态Mutex可以防止队尾延迟情况(队尾的goroutine迟迟获得不到锁)
- 当队列中的最后一个goroutine获得Mutex, 或队列中的任意一个goroutine等待时间小于阈值, Mutex从饥饿态切换回正常态
主体结构
- Group Workflow
- Group为一个缓存的命名空间, Cache <-> Name, 例如学生分数有一个score group cache
- 一个Peer拥有Groups -> map[
groupname]*Group
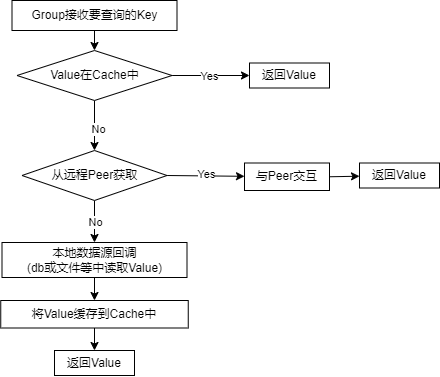
HTTP Server
- 规定访问路径格式为
/<basepath>/<groupname>/<key> - 打到Server的请求, Server在Groups里寻找Group, 然后group.get(key)
一致性哈希
- 目的
- 负载均衡策略
- 普通的hash为了确定某个peer, 需要mod n, 如果节点数发生变换, 所有hash都失效要重新计算(可能引起缓存雪崩)
- 原理
- 哈希环
- 将hash值映射到2^32空间中, 首尾成环
- 将peer(名称、ip等)的哈希值放到环上
- 每次查询key, 计算对应hash值, 在环上顺时针查找, 找到的第一个peer就是应选的节点
- 可能存在数据倾斜问题, 可能有大量的key都映射到了某一个peer上
- 通过增加虚节点解决, 一个peer生成若干个虚节点放到环上
- 哈希环
缓存击穿
- 缓存雪崩、缓存击穿、缓存穿透
- singleflight防止缓存击穿 (更轻量的互斥锁防止缓存击穿)
- singleflight 抑制重复的并发调用, 请求合并
- singleflight.Gourp.Do(
key string, fn func() (interface{}, error)), 保证Do无论被调用多少次, 指定的fn只会被调用一次 - 利用WaitGroup和Mutex实现请求阻塞, 用map来缓存结果
singleflight
Do
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
type call struct{
wg sync.WaitGroup
val interface{} // 记录fn的返回结果
err error // 记录fn的error
...
}
type Group struct{
mu sync.Mutex // 对m进行加锁
m map[string]*call
}
/*
对于一个进入的key, 如果它存在于m中, 则call.WaitGroup.Wait(1), 阻塞, 等待现有的fn完成, 复现其结果
如果不存在, 说明是第一次获取key, 执行fn, 同时将key对应的call加入m
fn完成后, 无论是阻塞的key还是执行的key都返回fn()的结果, 并且将call从m中删除
*/
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
// 后续相同的key进入
if c, ok := g.m[key]; ok {
g.mu.Unlock()
c.wg.Wait()
return c.val, c.err
}
c := new(call)
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
c.val, c.err = fn()
c.wg.Done()
g.mu.Lock()
delete(g.m, key)
g.mu.Unlock()
return c.val, c.err
}
DoChan
与Do类似, 不过是启用新的goroutine来调用doCall(fn), 不会阻塞等待第一个请求, 最终返回一个channel
sync.Once
- 保证一个函数f在整个程序的生命周期只执行一次 once.Do(
f func()) once入参的f是没有返回值的 - 使用场景
- 单例模式
- lazy load
- 并发安全的初始化
singleflight和sync.Once的区别
- singleflight只用在并发场景下, 同时有多个重复请求进行请求合并, 当请求结束时, 会delete(g.m, key), 下一次请求任会执行一次fn
- sync.Once始终保持f只被调用一次
protobuf序列化
- protobuf
- 使用
- 在.proto文件中定义数据结构, 然后用protoc生成go代码(跨平台, 也可以是其它语言)
- 在项目中引用生成的代码
- 使用
- JSON
This post is licensed under CC BY 4.0 by the author.