Paper Reading WinCLIP
Paper Reading WinCLIP
WinCLIP
- WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
- 无官方代码, 参考代码链接
- https://github.com/caoyunkang/WinClip
- https://github.com/zqhang/Accurate-WinCLIP-pytorch
Main Contributions
- Compositional Prompt Ensemble
- WinCLIP(zero shot)/WinCLIP+(few shot) architecture
- multi-scale spatial features aligned with language for zero-shot(few-shot) anomaly segmentation
Compositional Prompt Ensemble
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
template_level_prompts = [
'a cropped photo of the {}',
'a cropped photo of a {}',
'a close-up photo of a {}',
'a close-up photo of the {}',
'a bright photo of a {}',
'a bright photo of the {}',
'a dark photo of the {}',
'a dark photo of a {}',
'a jpeg corrupted photo of a {}',
'a jpeg corrupted photo of the {}',
'a blurry photo of the {}',
'a blurry photo of a {}',
'a photo of a {}',
'a photo of the {}',
'a photo of a small {}',
'a photo of the small {}',
'a photo of a large {}',
'a photo of the large {}',
'a photo of the {} for visual inspection',
'a photo of a {} for visual inspection',
'a photo of the {} for anomaly detection',
'a photo of a {} for anomaly detection'
]
WinCLIP architecture
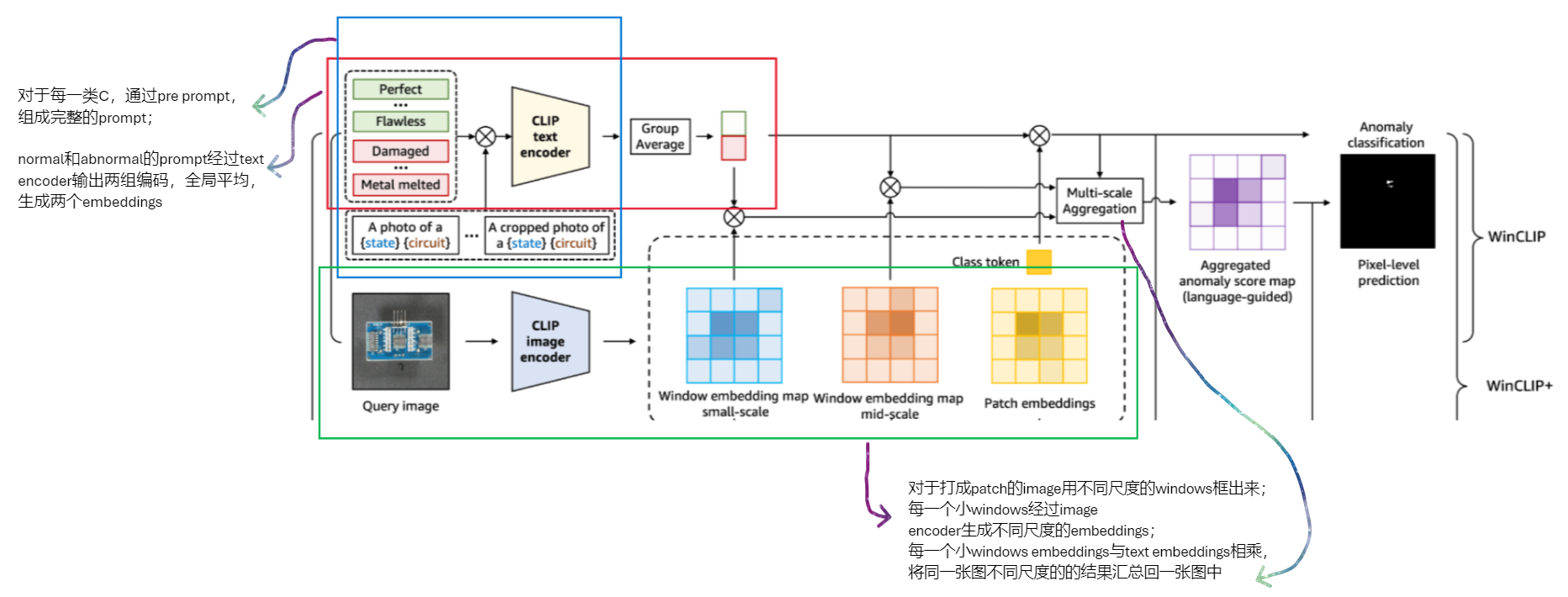
WinCLIP+ architecture
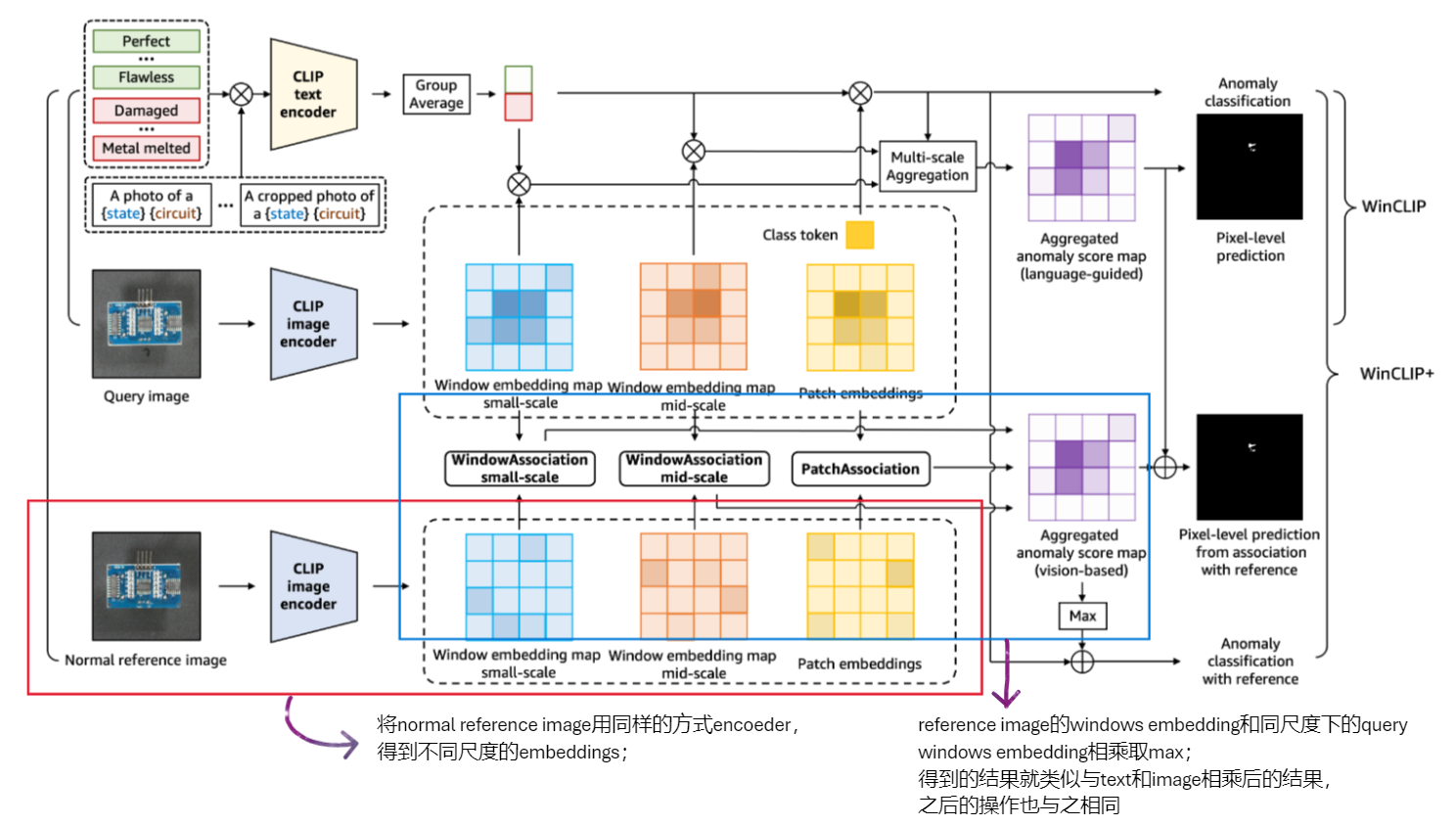
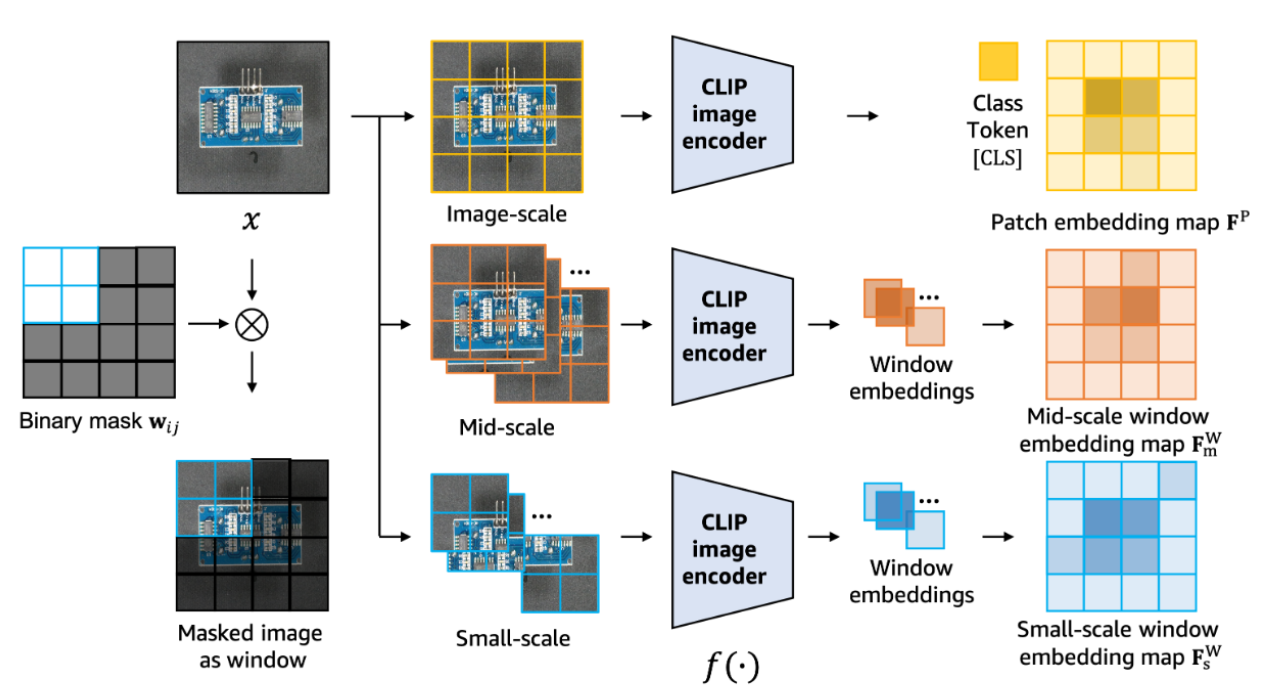
multi-scale windows
Code Analysis
bulid text prompt tokens and embeddings
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# generate text tokens
for template_prompt in template_level_prompts:
# normal prompts
for normal_prompt in state_level_normal_prompts:
phrase = template_prompt.format(normal_prompt.format(category))
normal_phrases += [phrase]
# abnormal prompts
for abnormal_prompt in state_level_abnormal_prompts:
phrase = template_prompt.format(abnormal_prompt.format(category))
abnormal_phrases += [phrase]
# 154个normal; 88个abnormal
normal_phrases = self.tokenizer(normal_phrases).to(self.device) # [154, 77]
abnormal_phrases = self.tokenizer(abnormal_phrases).to(self.device) # [88, 77]
# text encoder
normal_text_features = self.encode_text(normal_phrases) # [154, 640]
abnormal_text_features = self.encode_text(abnormal_phrases) # [88, 640]
windows transformer
generate window masks
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
index_mask = torch.arange(self.grid_size[0] * self.grid_size[1], dtype=torch.int64) # [1,2,3...] grid * grid num
index_mask = index_mask.reshape(self.grid_size[0], self.grid_size[1]) # [15, 15]
masks = []
scale_begin_indx = []
for scale in scales:
scale_begin_indx += [len(masks)]
for i in range(self.grid_size[0]):
for j in range(self.grid_size[1]):
# 越界
if i + scale > self.grid_size[0] or j + scale > self.grid_size[1]:
continue
masks += [index_mask[i:i + scale, j:j + scale]]
self.scale_begin_indx = scale_begin_indx
self.masks = masks
window masking
1
2
3
4
5
mask_xs = []
for mask in self.masks:
mask = torch.reshape(mask, [-1]).unsqueeze(0).to(x.device)
x_masked = torch.gather(x, dim=1, index=mask.unsqueeze(-1).repeat(N, 1, D)) # 根据index收集元素
mask_xs += [x_masked]
image encoder
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
mask_xs = self.window_masking(x) # len() = 365, mask_xs[i].shape = [83, 4 or 9, 896]
pooled_list, tokens_list = [], []
for scale_index in range(len(self.scale_begin_indx)):
if scale_index == len(self.scale_begin_indx) - 1:
scale_xs = mask_xs[self.scale_begin_indx[scale_index]:]
else:
scale_xs = mask_xs[self.scale_begin_indx[scale_index]:self.scale_begin_indx[scale_index + 1]]
mx = torch.stack(scale_xs, dim=0) # [196, 83, 4, 896]
n_windows, n_batches, _, _ = mx.shape
mx = mx.reshape((-1, mx.shape[2], mx.shape[3])) # [16268, 4, 896]
# append cls token # [16268, 1, 896]
# 用cls token记录这个windows中的全局信息
cls_tokens = self.class_embedding.to(x.dtype) + torch.zeros(mx.shape[0], 1, mx.shape[-1], dtype=x.dtype, device=x.device)
cls_tokens = cls_tokens + self.positional_embedding.to(mx.dtype)[0, :]
mx = torch.cat((cls_tokens, mx), dim=1) # [16268, 5, 896]
mx = mx.permute(1, 0, 2) # NLD -> LND
mx = self.transformer(mx)
mx = mx.permute(1, 0, 2) # LND -> NLD
pooled, tokens = self._global_pool(mx) # [16268, 896], [16268, 4, 896]
pooled = self.ln_post(pooled)
pooled = pooled @ self.proj # [16268, 896] @ [896, 640]
pooled = pooled.reshape((n_windows, n_batches, pooled.shape[1])) # [196, 83, 640]
tokens = tokens.reshape((n_windows, n_batches, tokens.shape[1], tokens.shape[2])) # [196, 83, 4, 896]
pooled_list += [p for p in pooled]
tokens_list += [t for t in tokens]
Anomaly Score Map
language guided anomaly score map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
scale_anomaly_scores = []
token_anomaly_scores = torch.zeros((N,self.grid_size[0] * self.grid_size[1])) # [83, 225] 225=15*15
token_weights = torch.zeros((N, self.grid_size[0] * self.grid_size[1])) # [83, 225]
for indx, (features, mask) in enumerate(zip(visual_features, self.masks)):
normality_and_abnormality_score = (100.0 * features @ self.text_features.T).softmax(dim=-1) # [83, 640] @ [640, 2]
normality_score = normality_and_abnormality_score[:, 0]
abnormality_score = normality_and_abnormality_score[:, 1]
mask = mask.reshape(-1) # [2,2] or [3,3] -> [4] or [9]
cur_token_anomaly_score = torch.zeros((N, self.grid_size[0] * self.grid_size[1])) # [83, 225]
cur_token_anomaly_score[:, mask] = (1. / normality_score).unsqueeze(1) # [83, 225]
# cur_token_anomaly_score[:, mask] = (1. - normality_score).unsqueeze(1)
cur_token_weight = torch.zeros((N, self.grid_size[0] * self.grid_size[1]))
cur_token_weight[:, mask] = 1.
if indx in self.scale_begin_indx[1:]:
# 记录当前尺度, 要换成下一个尺度了
token_anomaly_scores = token_anomaly_scores / token_weights
scale_anomaly_scores.append(token_anomaly_scores)
# another scale, calculate from scratch
token_anomaly_scores = torch.zeros((N, self.grid_size[0] * self.grid_size[1]))
token_weights = torch.zeros((N, self.grid_size[0] * self.grid_size[1]))
token_weights += cur_token_weight
token_anomaly_scores += cur_token_anomaly_score # len()==scale nums
# deal with the last one
token_anomaly_scores = token_anomaly_scores / token_weights
scale_anomaly_scores.append(token_anomaly_scores)
scale_anomaly_scores = torch.stack(scale_anomaly_scores, dim=0) # [2, 83, 225]
scale_anomaly_scores = torch.mean(scale_anomaly_scores, dim=0) # [83, 225]
scale_anomaly_scores = 1. - 1. / scale_anomaly_scores
anomaly_map = scale_anomaly_scores.reshape((N, self.grid_size[0], self.grid_size[1])).unsqueeze(1) # [83, 1, 15, 15]
return anomaly_map
image based anomaly score map(for few shot)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
scale_anomaly_scores = []
token_anomaly_scores = torch.zeros((N,self.grid_size[0] * self.grid_size[1]))
token_weights = torch.zeros((N, self.grid_size[0] * self.grid_size[1]))
cur_scale_indx = 0
cur_visual_gallery = self.visual_gallery[cur_scale_indx] # [196, 640]
for indx, (features, mask) in enumerate(zip(visual_features, self.masks)):
# 用reference image embedding features来计算, 其他部分几乎与text guided完全相同
normality_score = 0.5 * (1 - (features @ cur_visual_gallery.T).max(dim=1)[0]) # max( [83, 640] @ [640, 196], dim=1).shape = [83]
mask = mask.reshape(-1)
cur_token_anomaly_score = torch.zeros((N, self.grid_size[0] * self.grid_size[1]))
cur_token_anomaly_score[:, mask] = normality_score.unsqueeze(1)
# cur_token_anomaly_score[:, mask] = (1. - normality_score).unsqueeze(1)
cur_token_weight = torch.zeros((N, self.grid_size[0] * self.grid_size[1]))
cur_token_weight[:, mask] = 1.
if indx in self.scale_begin_indx[1:]:
# change to next scale
cur_scale_indx += 1
cur_visual_gallery = self.visual_gallery[cur_scale_indx]
token_anomaly_scores = token_anomaly_scores / token_weights
scale_anomaly_scores.append(token_anomaly_scores)
# another scale, calculate from scratch
token_anomaly_scores = torch.zeros((N, self.grid_size[0] * self.grid_size[1]))
token_weights = torch.zeros((N, self.grid_size[0] * self.grid_size[1]))
token_weights += cur_token_weight
token_anomaly_scores += cur_token_anomaly_score
# deal with the last one
token_anomaly_scores = token_anomaly_scores / token_weights
scale_anomaly_scores.append(token_anomaly_scores)
scale_anomaly_scores = torch.stack(scale_anomaly_scores, dim=0)
scale_anomaly_scores = torch.mean(scale_anomaly_scores, dim=0)
anomaly_map = scale_anomaly_scores.reshape((N, self.grid_size[0], self.grid_size[1])).unsqueeze(1)
return anomaly_map
generate reference image features
1
2
3
4
5
6
7
8
9
10
# reference image经过image encoder, 和query image的处理是一样的
self.visual_gallery = []
visual_features = self.encode_image(normal_images)
for scale_index in range(len(self.scale_begin_indx)):
if scale_index == len(self.scale_begin_indx) - 1:
scale_features = visual_features[self.scale_begin_indx[scale_index]:]
else:
scale_features = visual_features[self.scale_begin_indx[scale_index]:self.scale_begin_indx[scale_index+1]]
self.visual_gallery += [torch.cat(scale_features, dim=0)]
trick
1
2
3
4
5
# 在zero shot下visual_anomaly_map = textual_anomaly_map
if self.visual_gallery is not None:
visual_anomaly_map = self.calculate_visual_anomaly_score(visual_features)
else:
visual_anomaly_map = textual_anomaly_map
1
2
# 计算anomaly_map
anomaly_map = 1. / (1. / textual_anomaly_map + 1. / visual_anomaly_map)
Thoughts
- WinCLIP无需训练, prompts手动设计
- zero shot/few shot在这个模型架构下其实统一了, 更符合AD任务的真实场景
- template prompts并不能反应全部情况, 而且太多重叠的部分
- 会通过template生成100+个prompt, 这其中会包含a photo of [small/middle\lager] {class}, 有无必要性呢?
- 生成的score map是像素级别下的, 因此完全可以考虑将分割模块加入其中
- 用滑动窗口计算局部attention, 可不可以用Swin Transformer计算局部呢?
This post is licensed under CC BY 4.0 by the author.