Paper Reading VCP CLIP
Paper Reading VCP CLIP
VCP-CLIP
- VCP-CLIP: A visual context prompting model for zero-shot anomaly segmentation
- https://github.com/xiaozhen228/VCP-CLIP
Main Contributions
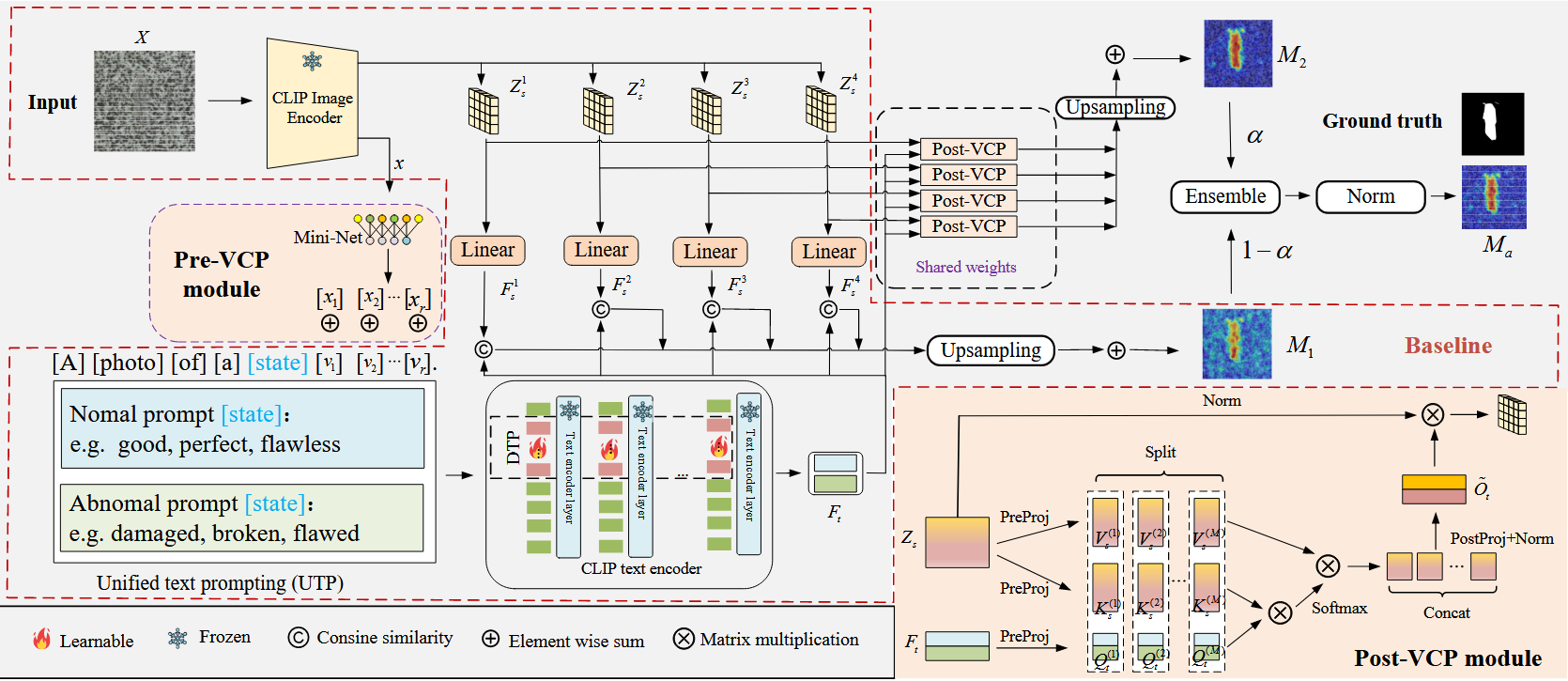
- pre-vcp, 用visual context生成text prompt中的[cls]部分, 避免了手工设计prompt时的描述过于复杂或过于简单的问题
- post-vcp, 设计用attention计算anomaly mask, 其中Q=text embedding, K, V=image dense features
- 总结了clip-based anomaly detection中的baseline architecture
- 总结了text prompt部分中的两种主要设计, Unified text prompting(UTP)和Deep text prompting (DTP)
- UTP: [a][photo][of ][a][state][v1][v2] · · · [vr]
- DTP: 在text encoder中, 用learnable embedding替换掉text embedding中的一部分
architecture
Code Analysis
pre vcp
UTP
- visual context embedding
1 2 3 4 5 6 7 8 9 10 11 12
B, C = img_feature.shape # [bs,768] global_feat = img_feature # mininet global_feat_new = self.prompt_linear1(global_feat.reshape(B, 1, C)) # [1,2,768] prompt_query = self.prompt_query + torch.zeros((B, self.prompt_query.shape[-2], self.prompt_query.shape[-1]), dtype=self.prompt_query.dtype, device=self.prompt_query.device) # [1,2,768] # use visual context if use_global: class_feature = prompt_query + global_feat_new else: class_feature = prompt_query return class_feature
- visual and text embedding fusion
1 2 3 4 5 6 7 8 9 10
# text embedding x = self.token_embedding(text).type(self.dtype) x_new = torch.zeros_like(x).to(x.device) # embedding fusion for j in range(x.shape[0]): x_new[j, :, :] = torch.cat([x[j, 0:pos_y[j], :], visual_feature[i, :, :], x[j, (pos_y[j] + 1):(self.context_length - visual_feature.shape[1] + 1)]], dim=0).unsqueeze(0) # [1,77,768] x_new = x_new + self.positional_embedding.type(self.dtype) # [1,77,768]
DTP
1
2
3
4
5
6
7
8
9
10
# dtp forward
deep_prompt_emb = self.prompt_dropout(self.prompt_proj(self.deep_prompt_embeddings[i - 1]).expand(B, -1, -1)).permute(1, 0, 2)
# concat prompt
hidden_states = torch.cat((
hidden_states[:1, :, :],
deep_prompt_emb,
hidden_states[(1 + self.num_tokens):, :, :]
), dim=0) # [77,1,768]
hidden_states, attn = self.transformer.resblocks[i](hidden_states)
post vcp
- attention
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# F_t=text, F_s=image B1, N1, C1 = F_t.shape # [1,2,768] B2, N2, C2 = F_s.shape # [1,1369,1024] assert B1 == B2 # text as q q_t = self.q_proj_pre(F_t.permute(0, 2, 1)).permute(0, 2, 1).reshape(B1, N1, self.num_heads, self.head_dim) # [1,2,8,128] # image as k, v k_s = self.k_proj_pre_1(F_s.permute(0, 2, 1)).permute(0, 2, 1).reshape(B2, N2, self.num_heads, self.head_dim) # [1,1369,8,128] v_s = self.v_proj_pre_1(F_s.permute(0, 2, 1)).permute(0, 2, 1).reshape(B2, N2, self.num_heads, self.head_dim) # [1,1369,8,128] # torch.einsum 矩阵乘法操作 attn_t = torch.einsum('bnkc,bmkc->bknm', q_t, k_s) * self.beta_t # [1,8,2,1369] attn_t = attn_t.softmax(dim = -1) F_t_a = torch.einsum('bknm,bmkc->bnkc', attn_t, v_s).reshape(B1, N1, self.dim_out) # [1,2,8,128]->[1,2,1024] F_t_a = self.proj_post_t(F_t_a.permute(0, 2, 1)).permute(0, 2, 1) #[1,2,1024] F_t_a = F_t_a / F_t_a.norm(dim=-1, keepdim = True) return F_t_a
- anomaly map
1 2
F_t_a = Zero_try(text_embeddings.permute(0, 2, 1), dense_feature) # [1,2,1024] anomaly_map_new = (Zero_try.prompt_temp_l1.exp() * dense_feature @ F_t_a.permute(0, 2, 1)) # [1, 1369, 2]
Thoughts
- UTP中的[state]能否不使用简单的”good/damaged” or “perfect/flawed”
- baseline architecture中的使用对比学习得出的anomaly map是否有可以去除
- 在encoder后直接接一个transformer(或单attention), 变成类似detr的结构, 完全由这个模块输出anomaly map和classification
- 缺少few-shot结构
- 可不可以用reference image的dense embedding嵌入到normal text的[state]或者直接替换normal prompt
- clip或许可以换成更适合密集型任务的clip变体
This post is licensed under CC BY 4.0 by the author.