Paper Reading SAM
Paper Reading SAM
SAM
- Segment Anything
- https://segment-anything.com
Main Contributions
- data engine (dataset SA-1B)
- phase 1: 完全人工标注的数据集, 训练sam
- phase 2: 半自动阶段, 输入图A, sam输出一个mask, 人工在输出mask基础上, 二次标注(完善标注, 此时模型的能力还不强), 人工+模型标注的mask作为图A的ground truth, 再用图A训练sam, phase 2结束后, sam已训练完成
- phase 3: 全自动阶段, 给新的大量无标注图片, 将sam生成的mask作为ground truth(还需要经过后处理, 如nms等操作), image和生成的mask作为SA-1B
- segment anything model
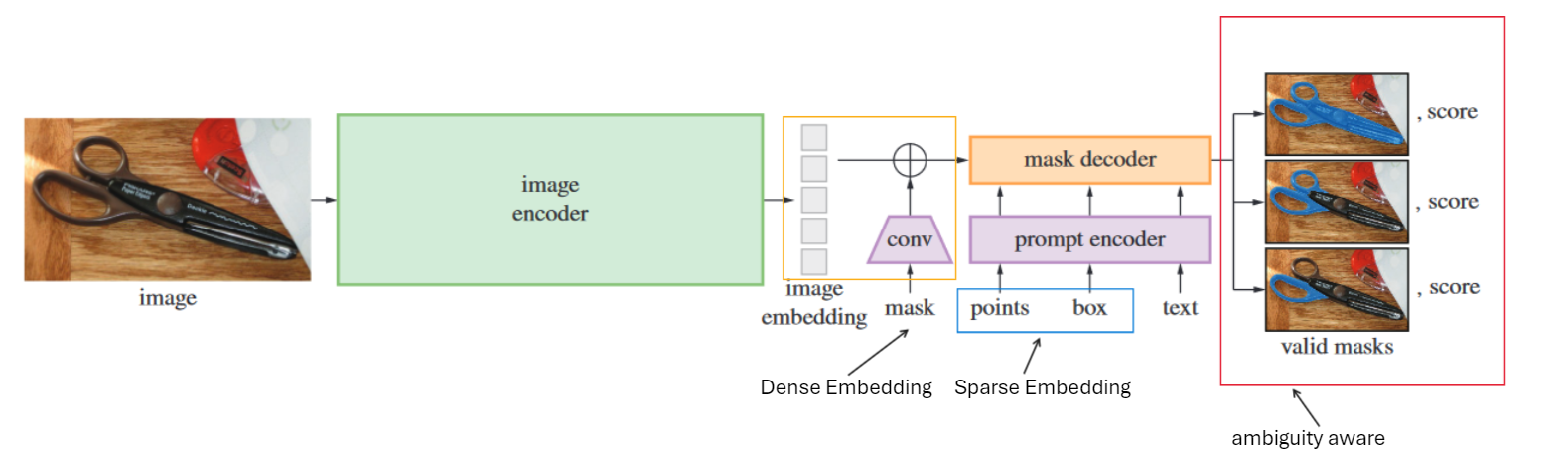
Code Analysis
image encoder
- 传统的ViT
prompt encoder
Sparse Embedding
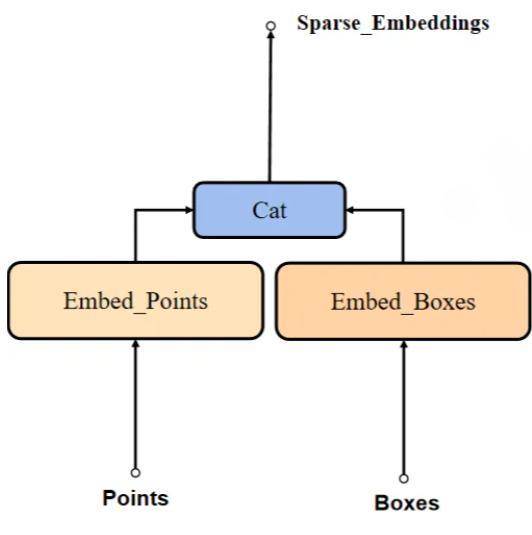
- point
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
def forward_with_coords( self, coords_input: torch.Tensor, image_size: Tuple[int, int] ) -> torch.Tensor: """Positionally encode points that are not normalized to [0,1].""" coords = coords_input.clone() coords[:, :, 0] = coords[:, :, 0] / image_size[1] # x坐标 coords[:, :, 1] = coords[:, :, 1] / image_size[0] # y坐标 return self._pe_encoding(coords.to(torch.float)) # 加位置编码 # B x N x C def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor: """Positionally encode points that are normalized to [0,1].""" # assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shape coords = 2 * coords - 1 # 坐标映射到transformer dim维 coords = coords @ self.positional_encoding_gaussian_matrix coords = 2 * np.pi * coords # outputs d_1 x ... x d_n x C shape return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)
1 2 3 4 5
point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size) point_embedding[labels == -1] = 0.0 point_embedding[labels == -1] += self.not_a_point_embed.weight point_embedding[labels == 0] += self.point_embeddings[0].weight point_embedding[labels == 1] += self.point_embeddings[1].weight
- 每个point坐标[x,y], 还有对应这个point的label[-1(忽略),0(背景),1(前景)]
- label为-1的点用作pad, 当没有box时, 添加pad
- box
1 2 3 4
coords = boxes.reshape(-1, 2, 2) # 一个框, 两个点坐标, 每个点坐标(x, y) corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size) corner_embedding[:, 0, :] += self.point_embeddings[2].weight corner_embedding[:, 1, :] += self.point_embeddings[3].weight
- 每个box是两个点[x0,y0,x1,y1], 转换为[n,2,2]后, 就等于把box转换成点来处理
- text
- 官方未实现, 第三方实现(sam改进, 变体)
- lang sam (Grounding DINO + clip)
- fastsam (YOLOv8-seg + clip)
Dense Embedding
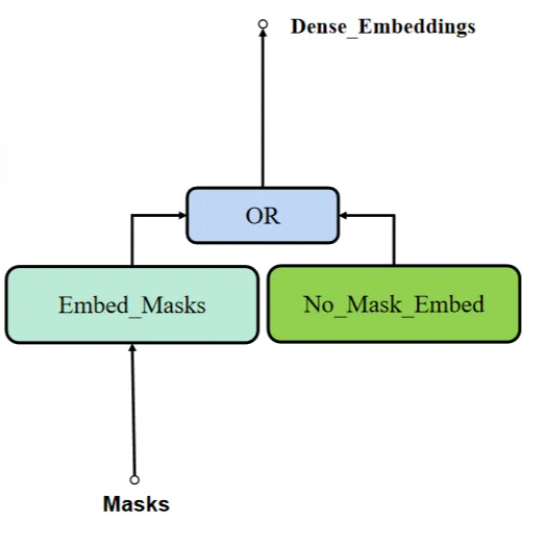
- mask
1 2 3 4
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor: """Embeds mask inputs.""" mask_embedding = self.mask_downscaling(masks) return mask_embedding
1 2 3 4 5 6
if masks is not None: dense_embeddings = self._embed_masks(masks) else: dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand( bs, -1, self.image_embedding_size[0], self.image_embedding_size[1] ) # [1, 256, 64, 64]
- 没指定mask时, 使用no_mask_embed
- 指定mask, mask下采样成image size
- mask和image相加作为decoder的输入
mask decoder
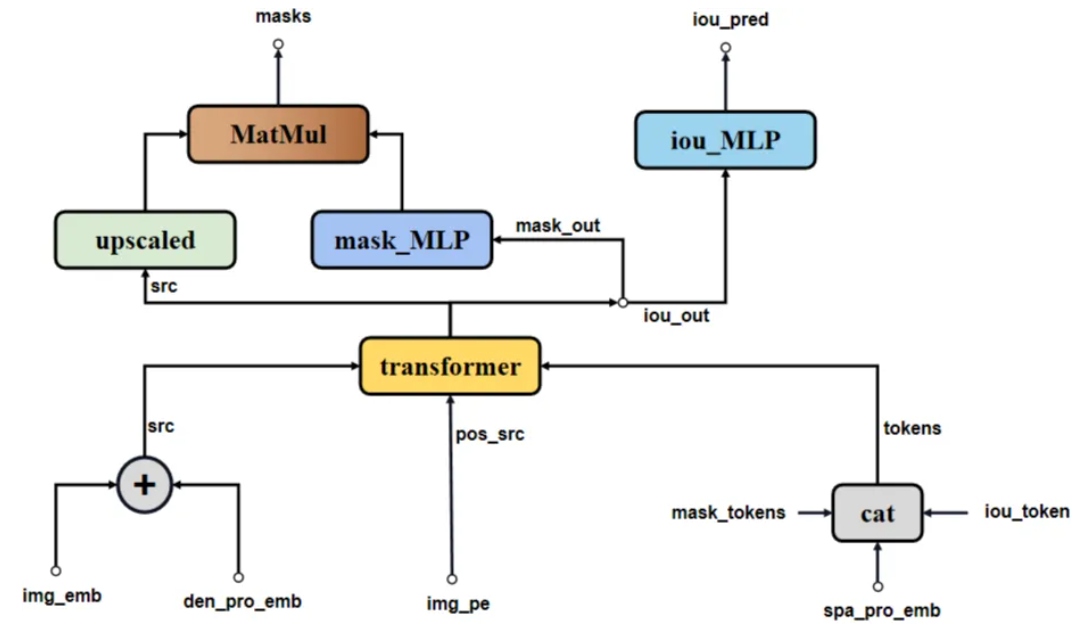
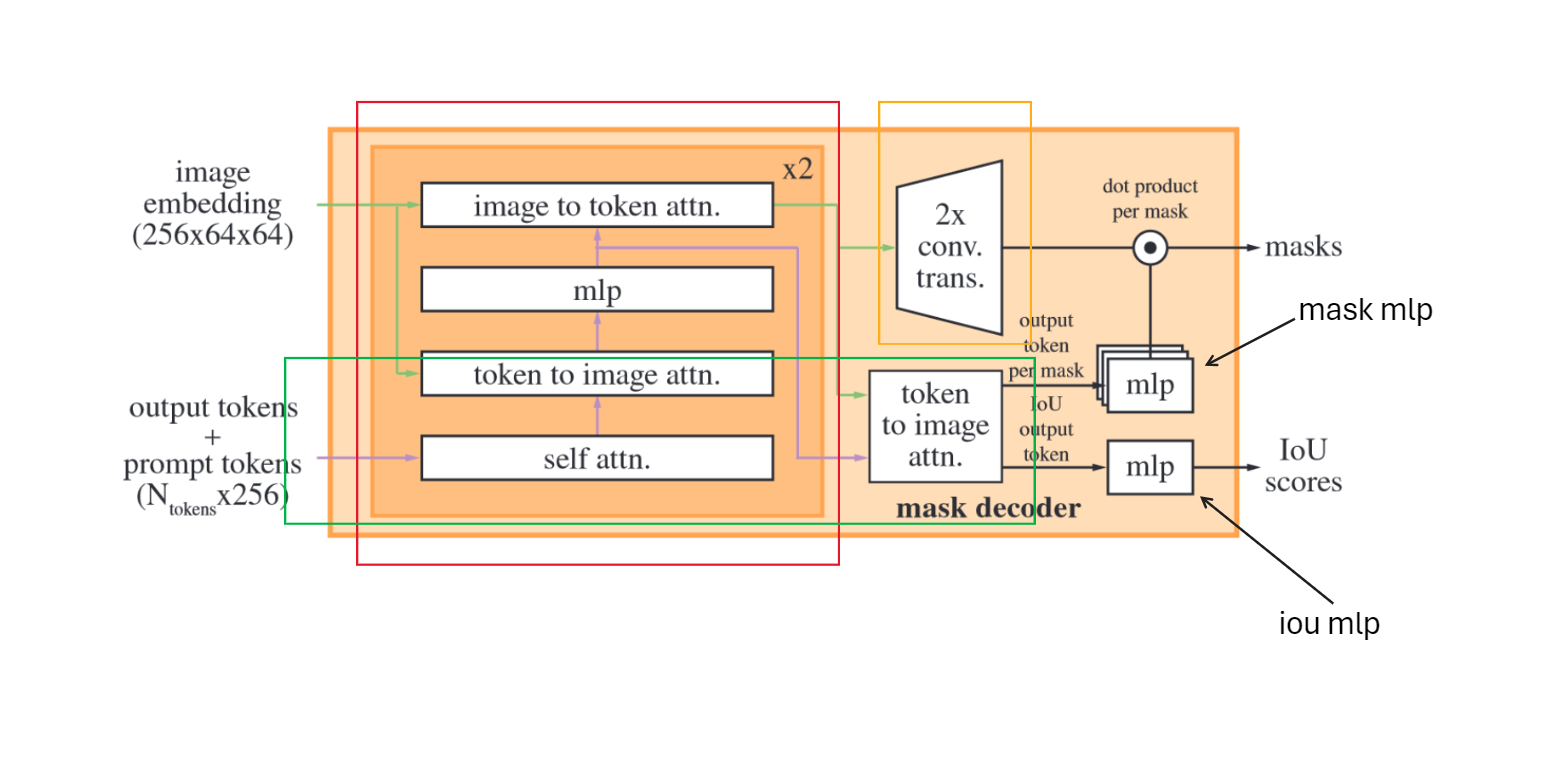
- 输入处理
1 2 3 4 5 6 7
output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0) # [5,256] output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1) # [1, 5, 256] tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1) # [1, 5 + S, 256] # Expand per-image data in batch direction to be per-mask src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0) src = src + dense_prompt_embeddings pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
- src: image embedding + mask embedding
- pos_src: image pos embedding
- tokens: iou_tokens + mask_tokens + sparse_prompt_embeddings(points embedding + box embedding)
- 正向传播
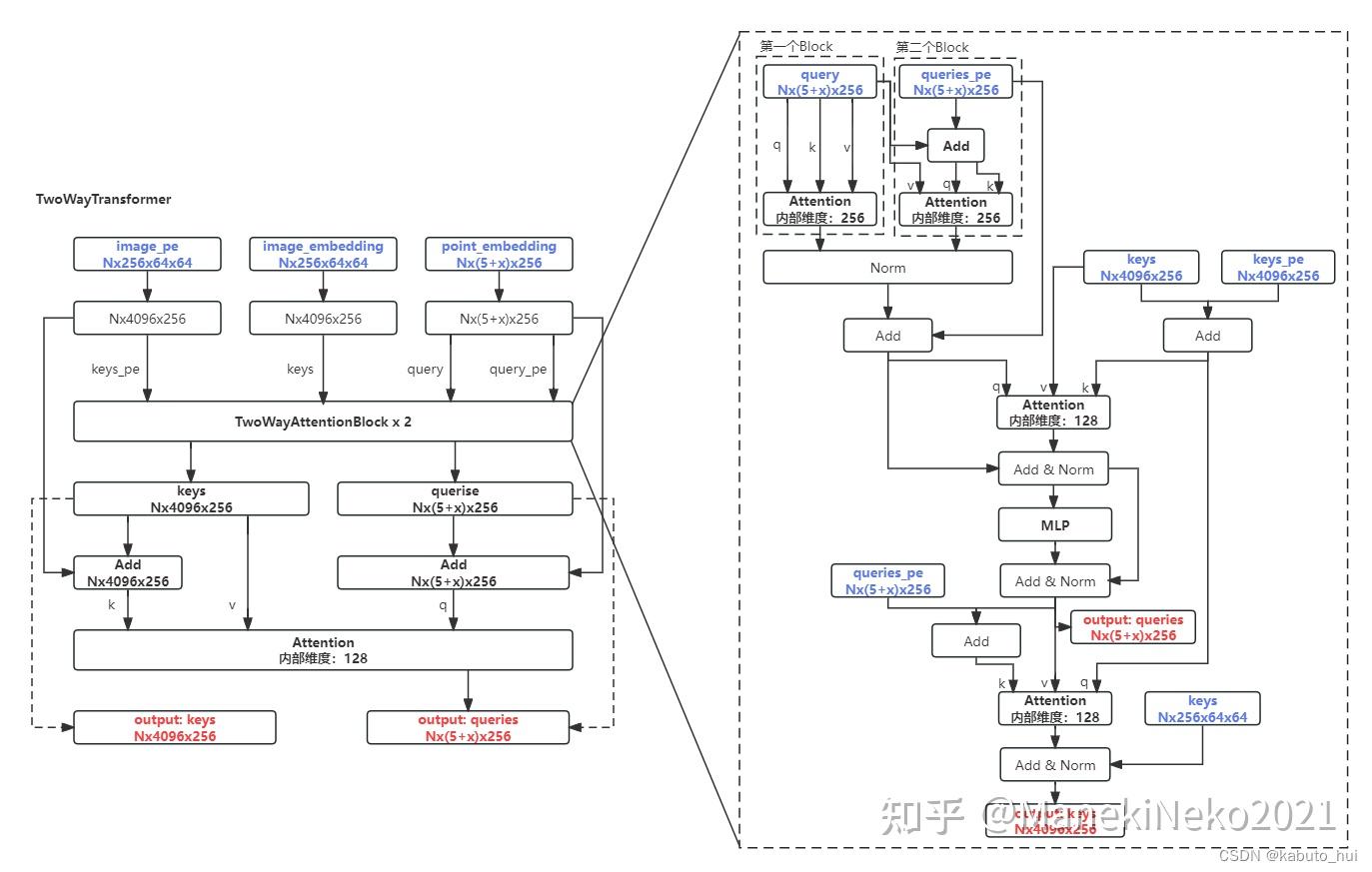
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# Cross attention block, tokens attending to image embedding q = queries + query_pe k = keys + key_pe attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys) queries = queries + attn_out queries = self.norm2(queries) # MLP block mlp_out = self.mlp(queries) queries = queries + mlp_out queries = self.norm3(queries) # Cross attention block, image embedding attending to tokens q = queries + query_pe k = keys + key_pe attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries) keys = keys + attn_out keys = self.norm4(keys)
- 输出结果
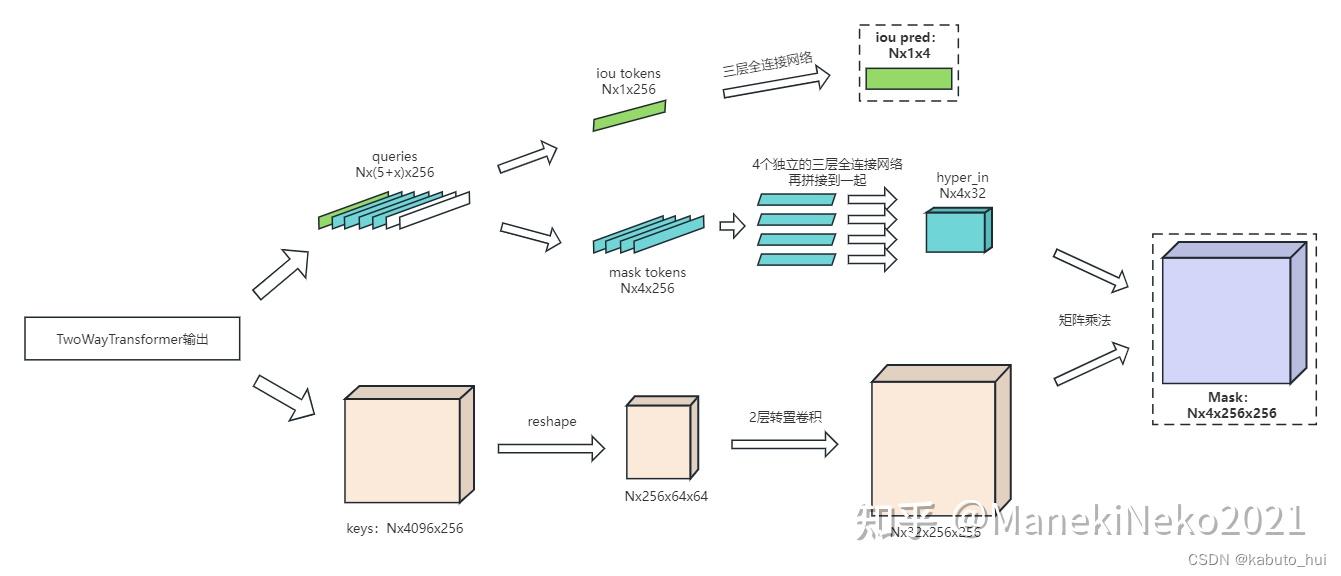
1 2 3 4 5 6 7 8 9 10 11 12 13 14
iou_token_out = hs[:, 0, :] # [1, 256] mask_tokens_out = hs[:, 1 : (1 + self.num_mask_tokens), :] # [1, 4, 256] # Upscale mask embeddings and predict masks using the mask tokens src = src.transpose(1, 2).view(b, c, h, w) upscaled_embedding = self.output_upscaling(src) hyper_in_list: List[torch.Tensor] = [] for i in range(self.num_mask_tokens): yper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :])) hyper_in = torch.stack(hyper_in_list, dim=1) b, c, h, w = upscaled_embedding.shape # [1, 4, 32] @ [1, 32, 256, 256] masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w) # [1, 4, 256, 256] # Generate mask quality predictions iou_pred = self.iou_prediction_head(iou_token_out) # [1, 4]
- hs
- hs提取出iou_token_out, mask_tokens_out
- iou_token_out对应每个mask_tokens的iou score
- mask_tokens_out与输出src做矩阵乘法, 得出输出mask, 这里的mask_tokens_out也是4维, 可以理解成做了多尺度的特征融合
- hs提取出iou_token_out, mask_tokens_out
- iou_tokens: [1, transformer_dim] 用来记录输出后每个mask的iou值
- mask_tokens: [4, transformer_dim] 用来记录输出后每个mask的特征, 为实现ambiguity-aware
- [dim 4] = 1(记录multimask_output=false) + 3(记录multimask_output=true)
- 这两个tokens可以理解问NLP transformer中的[cls], 用于记录输出tokens
- src
- 上采样4倍, 和mask_tokens_out融合后为输出mask
- hs
Automatic Mask Generation
1
2
3
4
5
6
7
8
9
10
# crop_box就是整张图的坐上和右下坐标
x0, y0, x1, y1 = crop_box
cropped_im = image[y0:y1, x0:x1, :]
cropped_im_size = cropped_im.shape[:2]
self.predictor.set_image(cropped_im)
# Get points for this crop
points_scale = np.array(cropped_im_size)[None, ::-1]
# self.point_grids就是a regular grid of 32×32 points on the full image, 即在整张图上撒了32x32个点
points_for_image = self.point_grids[crop_layer_idx] * points_scale
This post is licensed under CC BY 4.0 by the author.