Paper Reading AnomalyCLIP
Paper Reading AnomalyCLIP
AnomalyCLIP
- ANOMALYCLIP: OBJECT-AGNOSTIC PROMPT LEARN- ING FOR ZERO-SHOT ANOMALY DETECTION
- https://github.com/zqhang/AnomalyCLIP
Main Contributions
- AnomalyCLIP architecture
- object-agnostic text prompts
- DPAM layer (V-V attention)
- glocal abnormality loss function (global + local)
AnomalyCLIP architecture

- Train
- text
- prompt learner生成init promt, 将init prompt传给text encoder
- text encoder替换部分token embedding, 学习替换的部分, 修改init prompt
- image
- image通过img encoder生成全局的visual embedding, 和text embedding做cross entropy loss, 相当于为这个image输出一个分类标签(normal/abnormal)
- 通过DPAM layers, 用关注局部信息的attention与text embedding计算相似度, 得到相似度map, 相似度map与原图mask做segment loss, 相当于image的pixel level loss
- text
- Inference
- text
- prompt learner生成init promt
- text encoder用已经训练好的token embedding替换promt embedding, 生成text embedding
- image
- image通过vision encoder生成visual embedding和local visual embedding
- inference
- visual embedding和text embedding对齐生成分类结果
- local embedding和text embedding对齐生成segment mask
- text
object-agnostic text prompts
- 希望关注异常, 而不在乎异常出现在具体的物体上, 因此不需要关注对象语义信息
- [Ve] {cls} 改为 [Ve] {object}
- [We] {damaged} {cls} 改为 [We] {damaged} {object}
- 将可学习的learnable token embedding(t`m)嵌入到的第m层CLIP text encoder(Tm), 输出tm+1和r`m+1
- 丢弃r`m+1, 在tm+1的基础上重复操作, 虽然丢弃了r`m+1, 但是梯度依然能回传回t`m
DPAM layer (V-V attention)
- 对角线突出注意力图(diagonally prominent attention map)有助于改善局部语义信息local visual semantics
- 将Q-K attention替换为Q-Q, K-K, and V -V self-attention
glocal abnormality loss function (global + local)
- 将异常检测任务拆成两个部分, 全局分类(one-class)和局部分割(segment mask)
- 训练时计算local loss
- 推理时生成mask
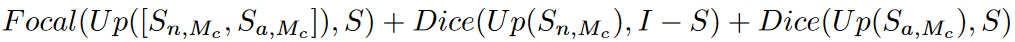

Code Analysis
DPAM替换origin attention
1
2
3
4
5
6
7
8
9
10
# 替换后DPAM_Layer_num层为DPAM Attention
def DAPM_replace(self, DPAM_layer_num):
if DPAM_layer is not None:
for i in range(1, DPAM_layer_num):
self.attn = Attention(self.embed_dim, self.embed_dim, self.num_heads, True)
self.attn.qkv.weight.data = self.transformer.resblocks[-i].attn.in_proj_weight.clone()
self.attn.qkv.bias.data = self.transformer.resblocks[-i].attn.in_proj_bias.clone()
self.attn.proj.weight.data = self.transformer.resblocks[-i].attn.out_proj.weight.clone()
self.attn.proj.bias.data = self.transformer.resblocks[-i].attn.out_proj.bias.clone()
self.transformer.resblocks[-i].attn = self.attn
DPAM Attention
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# DPAM Attention forward
# 先计算原始attention, 然后在将qk改成vv, 再算一个attention, 然后返回两个attention
def forward(self, x):
# pre code
# ...
# pre code
# original self-attention for the original path
# q-k attention
attn_ori = (q @ k.transpose(-2, -1)) * self.scale
attn_ori = attn_ori.softmax(dim=-1)
attn_ori = self.attn_drop(attn_ori)
# replace k & q by v
k, q = v, v
# self-attention, higher temperate for resnets performs better
# v-v attention
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = (attn).softmax(dim=-1)
attn = self.attn_drop(attn)
# post code
# ...
# post code
return [x, x_ori]
prompt learner
- 初始化这样两个prompt, 然后tokenize再embedding
- [‘X X X X X X X X X X X X object.’]
- [‘X X X X X X X X X X X X damaged object.’]
text encoder replace embedding
1
2
3
4
5
6
7
8
9
10
# x: text embedding
prefix = x[:1, :, :]
# self.compound_prompt_nctx == 4
suffix = x[1 + self.compound_prompt_nctx:, :, :]
textual_context = compound_prompts_deeper[counter]
# textual_context: nn.Parameter [4, feature_dim]
textual_context = textual_context.expand(x.shape[1], -1, -1).permute(1, 0, 2).half()
# Add the learnable tokens of this layer with the input, replaced by previous
# layer learnable tokens
x = torch.cat([prefix, textual_context, suffix], dim=0)
Thoughts
- 只有zero shot泛化能力, 实际上异常不止是damaged object, 例如电子元器件多了或者少了一点东西, 这也是异常, 而要检测这种异常few shot的能力是必要的
- WinCLIP, anomalyGPT等文章中都将模型架构设计成了zero和few shot 都有的架构, {??这两个能力是有一些割裂, 使用few shot时, zero shot的部分似乎作用就不大了??}
- 将异常检测试做全局分类和局部分割, 那是否融合SAM这种分割大模型来做分割呢
- prompt与对象语义无关, 但是只划分了object和damaged object, 可不可以用low level的描述呢, {??裂痕, 洞, 等??}
- SAA提出了4种prompt, 其中有领域专家知识来描述具体的缺陷
This post is licensed under CC BY 4.0 by the author.